
In my last post, I took you through the essentials of data science and some of the key steps involved in data preparation. Today, we’ll dive into one of the most powerful aspects of working with data: visualisation.
The Utility of Visualization in Data Analysis
Data visualization is not just about making your data look pretty; it’s about making your data understandable and actionable. But if you are anything like me then while you can appreciate a good visualisation, that doesn’t necessarily mean you can truly understand what’s going on in one.
I’m very tempted to write a blog post that goes through every kind of plot you can create and how to interpret that plot. But I would be reinventing the wheel way too much when there is an absolutely incredible resource out there: The Data Visualisation Catalogue. This web site has just about every kind of plot you can think of along with detailed explanations of them.
Instead what I’d like to do is to focus on usefulness. As I delved into data science and analytics, I really appreciated the way that a good visualisation helped me get my work done. It helped guide the data analysis process and allowed me to make smarter decisions about how to sort and clean and manipulate the data that I was working with. Yes, a good visualisation is super important if your ultimate deliverable is data and insights, but the main point here is that visualisation can be an incredibly useful tool even if you never plan to share the data with anyone else.
Practical Visualization Tools
Let’s use two types of plots as an example: scatter plots and histograms. You may or may not already know what they are. I’ll show you some examples below. However let’s think in terms of practical use. You have a bunch of data. Let’s say you don’t even know very much about the data except what you were able to gather from some of the techniques we talked about last time. You primarily use scatter plots to determine whether two features in your data set are correlated, or whether your data is clustered somehow. You use histograms to examine the way your data is distributed.
For example take this data set. Is there a linear correlation between feature 1 and feature 2 in the data? A scatter plot will tell you very quickly. But who cares if it’s correlated? Well, usually we are hunting around for relationships between features in our data. When you can quickly look at a scatter plot and recognize a linear correlation between two features, you know that you can probably find a mathematical relationship between them. But this is perhaps trivial if you are dealing with a data set with only two features in it, like “temperature” and “time of day”. But often you might be dealing with a data set that has many many features in it. Some of them are correlated to each other and some of them are not. Identifying the correlated features, and which features they are correlated with, is extremely useful. Seaborn provides a fantastic tool called the Pair Plot. It looks like this:

The pair plot basically takes all the numeric features (or columns) in a data frame and creates a scatter plot for each possible pair of them. Along the diagonal line, it gives you a histogram of that particular feature so you can see how its data is distributed. So in the example above, we can quickly say a few things: There definitely seems to be a linear correlation between flipper length and body mass (this is a data set representing statistics about a bunch of penguins). We can also see that flipper length doesn’t appear to have a normal distribution. There are two humps in the histogram. Hmm, I wonder why that is? Something to look into. Could it have something to do with why so many of the other scatter plots seem to have distinct clusters of data points? What’s that all about?
It sort of looks like, body mass and bill length have some linear correlation but they are correlated differently within each cluster. That’s weird. But it turns out that our penguin data consist of data on more than one species of penguin. Using a simple feature of Pair Plots, I can colour the plot based on penguin species. That yields this:

Ah, that makes more sense! You can see clearly now why the data appears to be strangely clustered. The ratios between different features of different species of penguin are not the same. But you can actually tell that the relationships are fairly linear for many of the features. Given the species and body mass of some given penguin, you can see that it’s probably quite possible to predict what its flipper length is going to be within a reasonable margin. I suggest you check out the page on Pair Plot on the Seaborn site to see just how feature rich this tool is.
Revealing Hidden Patterns with Visualization
When I first encountered the “hue” feature of Pair Plot that allowed me to see the categorical information hiding in my scatter plots, it was a bit of a eureka moment. I started playing around with this as part of my data exploration practice. If I found that my data’s scatter plot looked like a big fat lump, and my intuition told me there ought to be more correlation than I’m seeing, I would start colouring the scatter plots based on the value of some third feature, just to see if some clustering emerged like it did above in the penguin example.
Take this example data set. Let’s look at the scatter plot:
import seaborn as sns
import pandas as pd
df = pd.read_csv('scatter_histogram_data_with_categorical_feature.csv')
sns.scatterplot(data=df, x="feature1", y="feature2")
That does not look correlated at all. But now let’s look at it again, using hue to colour the data points according to the value of feature3:
sns.scatterplot(data=df, x="feature1", y="feature2", hue="feature3")
Would you look at that? It turns out that there is a sub-group of the data set, subgroup A, where feature 1 and feature 2 are very heavily correlated. You can see it in blue behind all the orange dots. This relationship was hidden in our initial plot but was revealed using a very simple visualisation technique. This could completely alter the course of our investigation and perhaps cause us to go and get more data on subgroup A. This bar chart shows us why the data was hidden:
sns.countplot(df, x='feature3')
Looks like our data set was biased toward subgroup B. Bias, by the way, is not a judgmental term. It’s a technical term. Bias is normal and it’s everywhere and good data analysis is always trying to uncover it because sometimes a truth about a minority data set can be masked by the overwhelming data available on the majority data set.
Understanding Image Data
During one of my first exercises while learning about Artificial Neural Networks, the task was to build a neural net that could categorize a bunch of images. In this case, it was using a pretty famous data set called the Fashion MNIST dataset. It contains a bunch of small greyscale images of various articles of clothing as well as a label that spells out the category of clothing it belongs to. You are supposed to train your neural network on a subset of the data set and see if it can become good at predicting the category that should be assigned to the remaining images.
As a bit of a newbie to all this, it seemed pretty mysterious to me how to apply what I had learned about data frames and arrays and stuff to an image recognition problem. I mean, I knew that images were stored as digital data, and data is data, right? But I really didn’t understand the very basics of how that works. I will share what I learned with you here.
So first, this may seem totally intuitive but I’ll say it anyway. A digital image is a file that contains data about each of the pixels in the image. The very simplest kind of image is a black and white image, because each pixel can either be black or white. That is, each pixel is either a zero or a 1. So take this very simple image of the letter A:

You could represent it numerically like this:
1 0 0 1
0 1 1 0
0 0 0 0
0 1 1 0Each white pixel is a 1 and each black pixel is a 0. If you were to take each of the rows of pixels and set them side by side instead of in a box, it would look like this:

So the sequence of pixels on the right is equivalent to the matrix of pixels on the left. It’s just arranged differently. Again if I convert black to 0 and white to 1, that means I can represent the image of the letter A as a series of 1s and 0s like this: 1001011000000110
So really, that image is just a sequence of numbers with values for each of the pixels. If the image was greyscale instead of black and white, the numbers would range from 0 for black to 255 for white, and all the shades of grey in between would be a number between 0 and 255. And that’s exactly what the MNIST fashion data set is. So you can imagine that for the purpose of data analysis and processing, we would basically create a data frame where each row was an image, and each column was a pixel in that image.
OK, so what does this have to do with data visualization? Well, first it was important to understand just how it is that a pandas dataframe can contain a bunch of images. Then it’s important to understand how to visualize the image data in that dataframe. Here is how I did that:
import numpy as np
import matplotlib.pyplot as plt
# If a dataframe contains pixel data, one image per row, it can be visualized by converting to an array
# then using matplotlib
#arr = np.array(df)
# Example of what a row might look like
row = np.array([0, 255, 255, 0, 255, 0, 0, 255, 255, 255, 255, 255, 255, 0, 0, 255], dtype=int)
# If the image is colour, it will have channels, so an extra dimension
# array may have columns that aren't pixels. Either drop those before you convert to array or skip them
# in the index specification below
plt.imshow(row.reshape(4,4), cmap = 'gray')Note what I mentioned in the comments above about channels. This was also another lightbulb moment for me. Don’t laugh. I’m not proud of my ignorance. But I assume I’m not the only one who never really stopped to think about this stuff. Hopefully by now you understand how a greyscale image can be encoded as a sequence of numbers from 0 to 255. But what about colour? Well, you probably already know that all colours can be produced through some combination of Red, Green and Blue (RGB). So if you take the same principle that we learned about greyscale and apply it individually to each of the primary colours, you can probably predict that you can use the values 0-255 not only for intensities of “white” but also for intensities of red, green or blue.
So in Green-land, 255 is VERY bright green, and 0 is black. In Red-land, 255 is VERY bright red and 0 is black. And so on. So if I could keep track of the intensity of each of the 3 primary colours for any given pixel in an image, I would basically be able to specify the colour of that pixel. The way this is done is by adding a dimension to the array that stores the pixel values. Call it the colour dimension. So instead of just a single array: [0, 255, 255, 0, 255, 0, 0, 255, 255, 255, 255, 255, 255, 0, 0, 255], you would have 3 arrays. One for red, one for green and one for blue, and these 3 arrays would be indexed into a container array. These layers are called channels. So you have something like:
greyscale_image = [0, 128, 255, 64, 32, 200, 123, 77, 180, 90, 45, 210, 155, 60, 220, 255]
colour_image = [
[255, 0, 128, 64, 32, 200, 123, 77, 180, 90, 45, 210, 155, 60, 220, 255], # Red channel
[0, 255, 0, 128, 64, 32, 255, 123, 77, 180, 90, 45, 210, 155, 60, 220], # Green channel
[128, 64, 32, 255, 0, 255, 123, 77, 180, 90, 45, 210, 155, 60, 220, 0]. # Blue channel
]To help illustrate, here’s an image that shows these channels as layers. (Note that the pixel values have been normalized to values between 0 and 1)
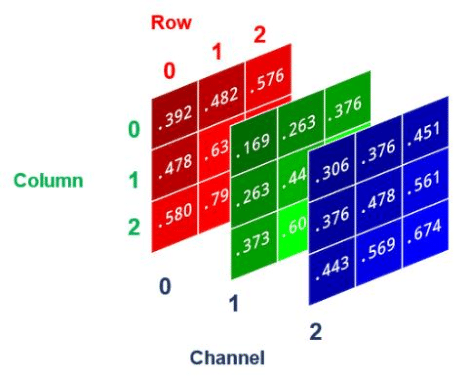
Useful Visualization Tips and Tricks
I hope you are not too frustrated with the side quest on image data encoding. It’s just something I personally had no clue about when I started, and it was quite a learning exercise for me. Part of what I’m trying to achieve in this blog is providing you with some shortcuts to some of the things I had to struggle with. Sometimes the struggle is worth it, but sometimes the basic facts are enough.
In that spirit, I will end this article with a few quick hints that I gathered for myself that are just useful reminders when I’m processing data. I keep these in a Jupyter notebook that I refer to when needed.
Some useful plots:
# Pie chart
thing_counts = df['thing'].value_counts().sort_index()
plt.pie(thing_counts, autopct='%1.1f%%')
# Correlation heat map
sns.heatmap(df.corr(), annot = True, cmap='coolwarm')
# Distribution of feature values
df.hist(bins = 20, figsize = (20,20), color = 'g')
# Pair plot (if you are classifying, try setting hue to your class column)
# this helps give you a sense of whether creating boundaries around the data will be hard.
sns.pairplot(df, hue='class_name')Visualising a grid of images from a dataframe.
# Assumes the data is sitting in a 2 dimensionall array called data_arr
# Define dimensions
nrows = 15
ncols = 15
fig, axes = plt.subplots(nrows,ncols, figsize = (17,17))
axes = axes.ravel() # Flattens the 15x15 matrix into an array of 225 elements
# This is meant to plot a randomly sampled grid of images from the data
for i in np.arange(0, nrows * ncols): # Evenly spaced variables
index = np.random.randint(0,len(data_arr)) # A random index within the range of data_arr
axes[i].imshow(data_arr[index,1:].reshape(28,28))
axes[i].set_title(data_arr[index,0], fontsize = 8)
axes[i].axis('off')
plt.subplots_adjust(hspace=0.4)
# If you want to highlight a cell based on some condition, here is some sample code:
for i in ...
if (some_condition) :
rect = Rectangle((0,0),1,1, transform=axes[i].transAxes,
linewidth=3, edgecolor='red', fill = False)
axes[i].add_patch(rect)There Is So Much More
One of the hardest thing about writing a blog, I have found, is to decide to leave things out of it. But alas it must be done. There are entire companies whose entire focus is on producing beautiful, informative data visualisations. We humans have evolved over millions of years to process vast amounts of information visually. This is why finding ways to see your data is so productive and can have such an impact on your work. And even the act of slowing down and thinking about how to visualise data can help you think about your data in different ways that could dramatically alter the course of your analysis. I hope that what I’ve shared with you about data visualisation has stimulated your appetite to learn more.
This post will be the last one focused on data science and analytics. The next time I write to you, I will share what I learned about Artificial Neural Networks, how to build them, train them and use them. Thank you for reading, and please leave your thoughts down below!


Hi Rached, absolutely data visualization is a great way to get insights, correlations and understad data and then decide the treatment you will do to it to have a good data set, also it helps to explain findings to team and customer, because as you said humans understand better when we visualize, looking forward for next post my friend.
Thank you for your continued engagement with me on this series Francisco. Do you think there’s anything I should have covered here that I didn’t?
Hi Rached no need to thank I appreciate your posts and just try to contribute with I have been learning, in general for a data visualization post think is good, there is so much detailed information in the web about different types of visualizations tools and graph types, I think maybe something missing and think is something important is talk about Box Plots and how those helps on detecting outliers and see if data is left or right skewed or even if it is almost normal distributed, this also implicate talking about quartiles Q1, Q2 (Median), Q3 and how typically we can identify an outliers (a value that goes more than 1.5 Q1 or Q3), this important because outliers can bias data sets and affect results when training models, behind this I think you cover the most important points of EDA (Exploratory Data Analysis) and benefits.